
こんにちは。KUSANAGI 開発チーム、プロダクトマネジャーの相原です。
KUSANAGI Tech Columnでは、WordPressやWebサイト運用に関する技術情報を発信しています。記事を丁寧に書くことは大切ですが、SNSなどで最初に興味を持ってもらうには、読む以外の入口も必要ではないかと考えていました。
その手段のひとつが、動画です。私も自分で動画を作ることはありますが、シナリオ、素材、撮影、編集と、慣れない作業も多く、気軽に始めるには少し重たい作業でもあります。
そこで今回は、以前公開した「WordPressセキュリティは「AI対AI」へ。猶予4時間時代に人間が選ぶべき生存戦略」をもとに、AIと対話しながらダイジェスト動画を作ることにしました。
動画制作の専用AIサービスは、いろいろあります。ただ今回は、あえてCodex CLIを使いました。対話しながら、思いどおりの、自分らしい動画をどこまで作れるのか。そこに挑戦してみたかったからです。
完成した動画は約108秒です。
対話を重ねることで、思っていた以上のものができました。
とはいっても、「AIに記事を渡せばすぐに完成動画が出てくる」。そういう実験ではありません。小さな改善を重ね、その過程を次回も使えるテンプレートへと育てていった話を紹介します。
最初の依頼は記事を短い動画にすること
元記事では、WordPressセキュリティを取り巻く変化として、次のポイントを取り上げています。
- 脆弱性公開から攻撃者のスキャン開始まで、深刻な事例では最短4時間
- サイト管理者がパッチを適用するまで、平均で約14日
- AIによるフィッシング、マルウェア、音声詐欺の高度化
- 更新が止まった「ゾンビプラグイン」とサプライチェーン攻撃
- 受動的防御から、WAF、仮想パッチ、自動更新、多層防御を組み合わせた能動的防御への転換
これらを動画にするとき、最初から凝った編集は目指さず、記事の要点を最後まで一本に作りきれるかを確かめたいと考えました。
まずAIに、記事のURL、やりたいこと、アバターの画像を渡しました。すると、記事を約90秒のナレーションへ要約し、6つのシーンに分けることを提案してくれました。これを受けて、各シーンに背景画像、見出し、アバターを配置し、音声に合わせて動画にするところまで依頼しました。
仮音声には、Windows標準の読み上げ機能を使いました。ナレーションをシーンごとに分割し、音声ファイルを生成して連結するスクリプトは、細かく指示しなくてもAIが作ってくれました。
映像側では、Pythonの画像処理ライブラリPillowで背景、見出し、字幕、アバターをフレーム単位で合成し、ffmpegでMP4へ変換しています。ただし、この方式にすぐ行き着いたわけではありません。
初回の動画生成がなかなか出来上がらないので、「ずいぶん時間がかかるな」と思ってディレクトリを見てみると、途中のフレームが連番PNGとして大量に書き出されていました。慌てて処理を止め、AIに別の方法がないか聞きました。
そこでAIが提案したのが、フレームをrawvideoとしてffmpegへ直接渡す方法です。
背景画像、見出し、字幕、アバター
↓ Pillowでフレーム合成
rawvideo
↓ ffmpeg
MP4(1920x1080、12fps、H.264)途中のPNGでディスク容量を使わずに済み、修正と書き出しのサイクルを回しやすくなりました。詰まったところを相談すると、すぐに別の手が返ってくる。対話で進める良さを、最初に感じた場面でした。
一気に完成させず、まず静止画で見る
最初のセッションでは、毎回、完成動画を書き出していたわけではありません。配置を変えるたびに、AIが静止画のプレビューを出してくれます。完成動画を待たずに方向性を確かめられるので、私は要所に目を通しました。
たとえば最初のレイアウト案では、アバター、背景、タイトルの位置関係を見ました。

そこから、おさまりの悪かったアバターを円で囲み、字幕を入れ、見出し位置を調整しました。

背景画像もそのまま採用したわけではありません。最初の背景にはWordPressロゴが入っていましたが、商標上の懸念を避けるため、汎用的なCMSセキュリティの表現へ差し替えました。
補助字幕も、シーンが始まった瞬間から出すのではなく、ナレーションの該当箇所に近いタイミングで出すように変更しました。
小さな修正ですが、こうした判断を積み重ねると、動画は少しずつ「使えるもの」に近づきます。
動かせば自然になる、とは限らなかった
専用のAIサービスを使えば、アバターに自然な動きを付けることもできます。ただ今回は、Codex CLIとの対話と手元の素材で、どこまで自然に見せられるかを試したいと思いました。手を振る、PCを持つ、指差しといった画像を用意し、口の開閉やまばたきも作って、話しているように見せようとしました。
ところが、動かすほど不自然になります。上下に揺らすと宙に浮いて見え、指差し画像を細かく切り替えると振動して見えました。口パクも、音声とは関係なく一定周期で動くので、合っていないとかえって気になります。
結局、動きは思い切って減らしました。完成版では、PCを持ったアバターを右下に固定し、約5秒間隔のまばたきだけを残しています。指差しは、役割がはっきりしている最後の誘導カードでだけ使いました。動きを増やすより、「その動きには役割があるか」を考えて減らす方が、自然に見えました。
やはり、自分の声で話したくなった
実は、最初から自分の声で話したい、という野望はありました。ただ、そこから入ると、動画の流れを組み立てる前に行き詰まってしまいます。最初から完成は目指さない。まずは読み上げ音声で、最後まで動くものを作ることを優先したわけです。
映像が形になってくると、やはりどうしても実現したくなりました。自分の記事を紹介する動画なら、自分の声で話したい。
そこで、ボイスクローンを使えるサービスを探しました。その結果、Fish Audioで自分の声をもとにした音声を簡単に生成できることがわかりました。
まずAIに学習用の読み上げテキストを作ってもらい、私がそれを読み上げて音源を用意しました。その音源をFish Audioに学習させて自分の声のクローンを作り、今回のナレーション原稿を読み上げさせています。クローン音声は、自分で読み上げた音源だけでは精度が足りませんでした。Fish Audioが提示する読み上げ用の文章も追加で録音すると、精度がぐっと上がりました。
読み上げには、文字どおりに読ませるだけでは解決しない問題もありました。例えば、WAFは「ワフ」と読ませます。WordPressセキュリティもイントネーションが崩れやすいため、音声生成側で表記や区切りを調整する必要がありました。ただ、かなり優秀でこの2箇所の修正だけで自然なナレーションができあがりました。
ボイスクローンという技術があることは、知っていました。ただ、自分の声で実際に試すと、知っているのとは別の驚きがあります。冒頭の動画の声、どうでしょうか。セミナーで話している、いつもの私の声とほとんど同じではないでしょうか。
これだけ近い声を手元で作れるのは、便利です。同時に、改めて扱いには注意がいるとも感じました。本人がいないところで、本人の声を再現できるということでもあるからです。誰の声を、どこまで、何に使うのか。そこはしっかりと決めて運用すべきだと思います。
さて、生成した音声をAIへ渡すと、AIはその長さに合わせてシーンの尺と字幕のタイミングを調整し、動画を作り直してくれました。この尺あわせが一発でできたのはちょっとした驚きでした。
2回目は音声OFFでも伝わる動画へ
こうして最初のセッションで、背景が切り替わり、アバターが話し、見出しと補助字幕が表示される約98秒の動画ができました。
ただ、ビジネス用途で公開するにはまだ足りない。それは、作っている最中から気づいていました。それでもこのセッションでは、まず一通り通すことを優先したのです。一度かたちになって、これはいけそうだと思えたところで、頭の中にあった完成形へ近づけることにしました。
気になったのは、音声をOFFにしたときの見え方とわかりやすさです。いまの状態では、画面だけで記事の要点を追えません。見出しと補助字幕はありますが、内容の構造までは伝わらないのです。
そこで2回目のセッションでは、動画を「アバターが話す映像」ではなく、「読みやすいセミナー資料の連続」として作り直すことにしました。
改善の幅は大きかったのですが、作業は驚くほどスムーズでした。最初のセッションで、シーン構成、音声、字幕、動画生成の仕組みまで、土台がしっかりできていたからです。
完成版では、画面を次の4つに分けています。
- 上部: そのシーンの結論を示す見出し
- 中央: 数字比較、タイムライン、サプライチェーン、対策レイヤーなどの図解
- 下部: ナレーションに合わせて切り替わる常時字幕
- 右下: PCを持ったアバター
私から出した指示はシンプルです。重要な言葉は強調する。文字だけでなく、セミナー資料のように図やグラフも使う。
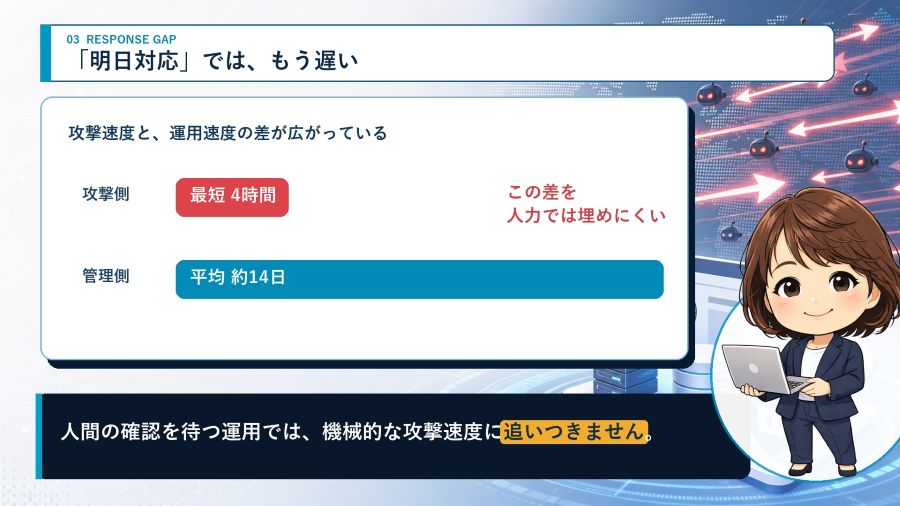
例えば「攻撃側は最短4時間、管理側は平均約14日」という差を、2本のバーで見せる。文章で読むよりも直感的に伝わります。これもAIが選んだ見せ方でした。
CodexはImage GenでGPT-Image-2の高品質な画像生成を行うことができるので、実力を十分に発揮してくれ、全てのシーンで修正なしの図解ができあがりました。
冒頭でつかみ、最後にひと押し
最後は、YouTubeで見るような品質に近づける仕上げです。
この段階の動画は、再生するとすぐにナレーションが始まり、テーマを把握する前に話が進んでしまいます。入口が弱いので、冒頭に、本編へクロスフェードするタイトルカードを足しました。
末尾には、記事タイトルとURL、「続きはコラムで」を載せた誘導カードを置きました。ここではアバターもPC保持から指差しへ切り替え、変化をつけています。

本編では落ち着いて解説し、最後だけ明確に行動を促す。場面ごとに、アバターの役割を分けました。
試行錯誤を次回のテンプレートへ
ここまでの試行錯誤を、1本きりで終わらせるのはもったいない。次の記事にも応用できるよう、テンプレートにまとめました。
テンプレートでは、固定する部分と、記事ごとに変える部分を分けました。動画の形式やレイアウト、冒頭と末尾の構成は固定します。シーン構成や字幕、強調語、背景画像、図解、記事タイトルやURLは、記事ごとに差し替えます。
それでも、完全な自動生成にはしていません。記事のどの数字を見せるか。何を図解するか。最後に読者へ何をしてほしいか。そこは記事ごとに考えた方が、伝わる動画になります。
AIとの動画制作で、人間が担当すること
今回、私はコードを書かず、AIとの対話で動画を作りました。
AIは、記事の要約からナレーション案、画像の配置、動画生成、プレビューの書き出し、音声の尺合わせ、テンプレート化まで担当しました。
では、人間は何をしたのか。見たときの違和感を見つけ、その理由を言葉にすることです。宙に浮いて見える、振動して見える、口が音声と合っていない、音声をOFFにすると内容を追えない。そう感じた理由を具体的に言葉にすると、AIはそれを次の生成に反映してくれます。
まず動くものを作る。見て、違和感を伝える。少し直す。もう一度見る。この反復で、動画だけでなく、動画を作る方法そのものを育てられました。
さらに、その判断をドキュメントに残せば、改善は1本の動画だけで終わりません。次の制作で使える工程になります。
これは、これまで私がAIと進めてきたコーディングの進め方とおなじです。AIとのしごとの進め方のスタイルがだいぶできてきたなぁ、と思います。
重たく感じていた動画づくりも、この進め方なら、ずいぶん身軽になります。効率が上がれば、たとえば英語版の動画にも挑戦できる。できることは、まだ広がりそうです。
身構えなくても、対話を重ねていけば、ずいぶん遠くまで行けます。やってみたいと思った方の、最初の一歩になればうれしいです。
追記~英語版も作ったよ
自分の音声モデルに英語ナレーションを読んでもらって動画にしたのがこちら。日本語サンプルから英語生成しているので、発音がカタカナ英語みたいになってたりちょっとあやしかったりしますが、多分私が読み上げてもこれ以上にはならないんじゃないかな..
一つ作れば簡単に多言語化できるっていいですね
